一句话结论:
Claude Opus 4.6的核心优势在于长上下文稳定性、复杂任务持续执行能力和安全治理框架;GPT-5.3在编程基准与速度体验上依旧强势。对企业团队来说,真正的问题不是“二选一”,而是怎么把两者放进同一条交付链路。
最后更新时间:2026-02-07
一、发布当晚发生了什么:为何话题迅速聚焦到对比
Claude Opus 4.6 发布后,讨论热度几乎立即集中到三件事:一是基准成绩是否真能转化为真实生产力,二是和 GPT-5.3 在代码任务里的差异到底有多大,三是这次安全策略是否会明显牺牲可用性。从公开信息看,Claude Opus 4.6 的定位很明确:不是单轮问答更“惊艳”,而是面向长任务、长上下文、可持续协作的“耐力型”模型。
很多开发者把 Claude Opus 4.6 的首发体验描述为“结构化能力更强,做大任务更稳”,也有人指出 GPT-5.3 在工具调用节奏、响应速度和代码修复闭环上更灵活。把这些反馈合起来看,会发现 Claude Opus 4.6 和 GPT-5.3 的差异已经从“答案谁更好”转向“谁在不同阶段更省团队时间”。
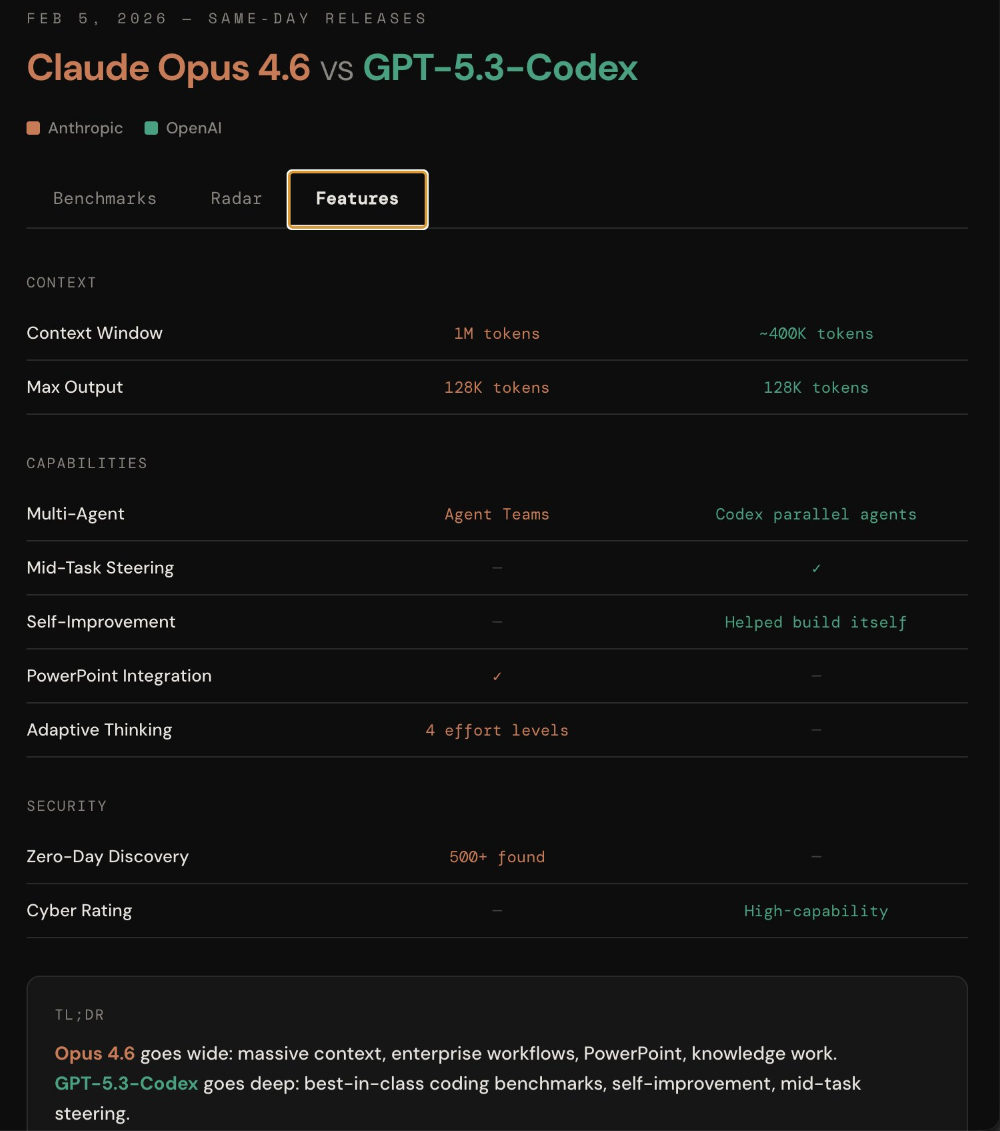
| 维度 | Claude Opus 4.6 | GPT-5.3 |
|---|---|---|
| 目标定位 | 长上下文、长周期智能体任务 | 强编程反馈速度与基准竞争力 |
| 首发讨论焦点 | 100万 token 测试、并行智能体、对齐 | 代码实测通过率、调用效率 |
| 团队价值 | 大项目连续推进与风险控制 | 研发迭代速度与单次产出效率 |
如果你的团队处于需求频繁变更阶段,GPT-5.3 往往更容易拿到“当日可交付”;如果你的团队面临超长文档、跨模块依赖和多角色协同,Claude Opus 4.6 的优势会更快显现。
二、100万 token 到底值不值:长上下文能力的实战意义
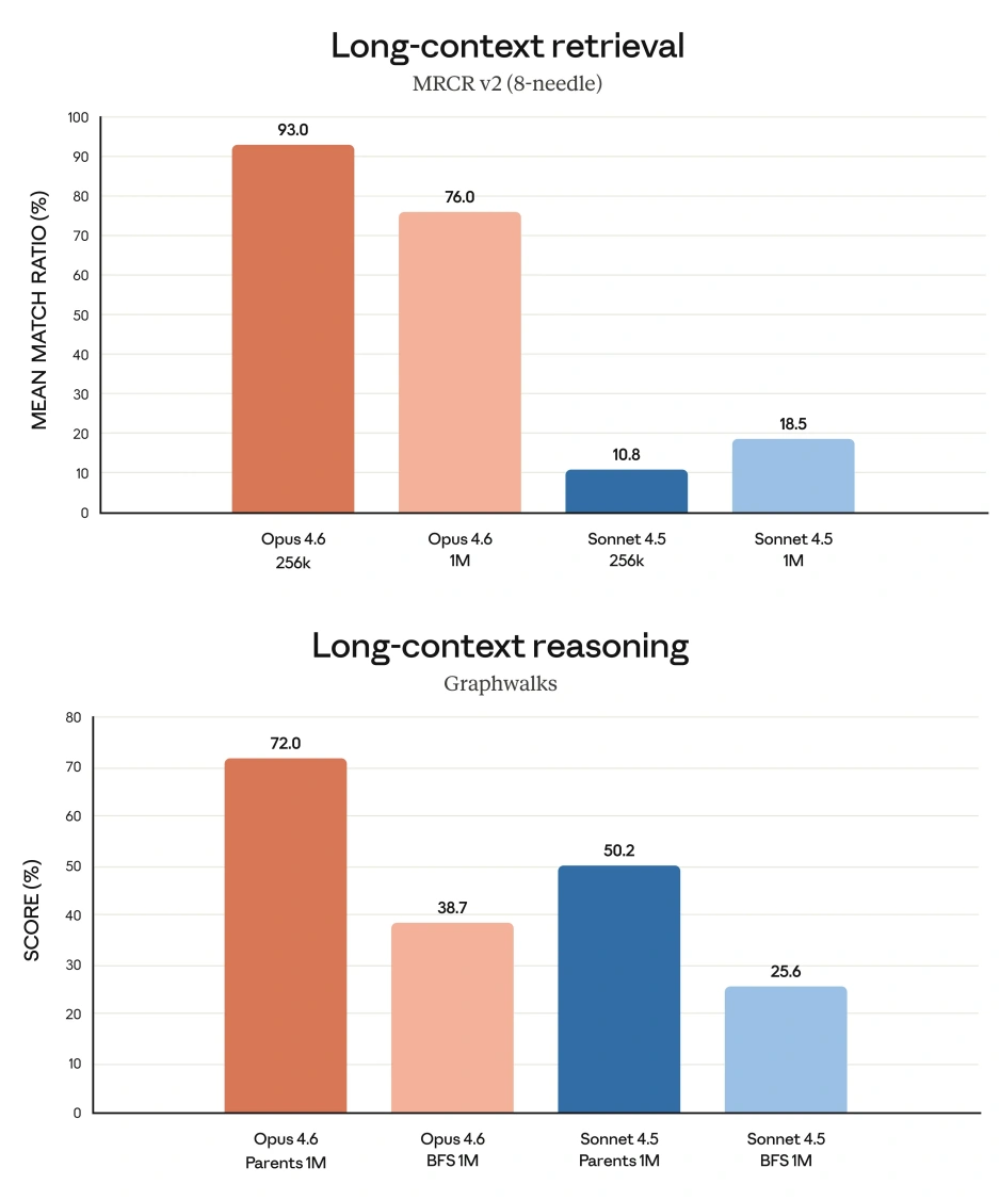
Claude Opus 4.6 的一个关键卖点是 100 万 token 上下文测试能力。数字本身不等于价值,价值在于“长文档读完后还能不能持续准确”。很多团队在模型落地时踩过同一个坑:上下文一长,模型会出现信息漂移,前后约束开始松动,后半段输出与前面冲突。Claude Opus 4.6 这次重点解决的就是这个问题。
公开材料里提到的 MRCR v2 “8 针-100 万”测试,本质上是检索+记忆一致性联合考验。Claude Opus 4.6 在这类任务上分数明显高于同系中档模型,说明它在“读得多”之外,确实改善了“记得住、连得上”。这对合同审阅、代码仓总览、跨文档技术调查特别关键。
在实际流程里,Claude Opus 4.6 比较适合承担“上下文主引擎”角色,常见用法是把需求文档、历史方案、接口协议、事故复盘一起喂入,让模型输出统一执行框架,再把编码环节拆给更快的模型并行处理。这样做能减少多人协作时的语义偏移,尤其适合跨组项目。
三、安全与可用性:这次不是二选一
很多模型升级会陷入一个老问题:安全收紧后,误拒率上升,正常任务也被拦。Claude Opus 4.6 的信息里有两个值得注意的点,一是强调行为失范率控制,二是继续压低过度拒绝率。换句话说,Opus 4.6 想把“可控”与“可用”同时维持在高位。
对企业来说,这比榜单名次更关键。原因很简单:研发和运营场景中的风险并非只来自“模型回答错了”,也来自“模型该答不答”或者“在高压场景发生异常迎合”。Opus 4.6 把安全评估扩到更细颗粒度,再配合网络安全探测工具,目标是让平台有可观测、可拦截、可回溯的治理路径。

如果你的业务触及金融、法务、代码安全审计等高风险链路,Opus 4.6 的这套策略会直接影响上线速度,因为合规审批往往最关注“是否可解释、是否可追踪、是否可限权”。
四、API 与 Claude Code 更新:并行智能体怎么真正落地
Claude Opus 4.6 的另一层价值来自工具链。单个模型再强,也很难替代工程流程;流程能不能跑通,取决于调度、监控、回滚和成本控制。Claude Opus 4.6 这次给出的自适应思考、算力分档、上下文压缩、长输出能力,本质上是在给工程团队更多“运行时旋钮”。
下面是一个简化调用示例,演示 Claude Opus 4.6 在“常规走高性能、疑难自动加深推理”的配置思路:
{
"model": "claude-opus-4-6",
"reasoning_mode": "adaptive",
"compute_tier": "high",
"context_compression": {
"enabled": true,
"threshold_tokens": 170000
},
"max_output_tokens": 64000
}
如果你要把 Claude Opus 4.6 放进多智能体流水线,可以按“总控-执行-审计”三层拆分:
# 1) 总控智能体:解析任务与约束,输出可执行计划
agent run orchestrator --model claude-opus-4-6 --input spec.md
# 2) 执行智能体:并行处理代码、测试、文档子任务
agent run worker-code --model gpt-5-3 --input task-code.json
agent run worker-test --model claude-opus-4-6 --input task-test.json
# 3) 审计智能体:合并结果并做风险检查
agent run auditor --model claude-opus-4-6 --input merged-result.json
实践里经常失败的点有两个:任务划分不独立、共享上下文管理混乱。Opus 4.6 适合做“共享语义中枢”,把不可并行的部分先收敛,再放给多个执行智能体分头推进。
五、两周 2000 次会话做编译器:这组数据该怎么读
Claude Opus 4.6 最出圈的案例,是多智能体在约两周里推进接近 2000 次会话,完成约 10 万行规模的 C 编译器工程。很多人只看到“速度快”,但更有价值的是它披露了真实工程约束:需要严格测试框架、需要清晰角色分工、需要持续状态文档,否则并行会互相覆盖。
| 指标 | 披露数值 | 对团队的启示 |
|---|---|---|
| 周期 | 约 2 周 | 适合冲刺型研发任务 |
| 会话量 | 近 2000 次 | 必须有自动化日志与追踪 |
| 输入/输出 | 约 20 亿 / 1.4 亿 token | 成本控制要前置设计 |
| 成果规模 | 约 10 万行 | 更像“工程协同能力验证” |
| 测试表现 | 多数测试高通过率 | 质量依赖测试框架而非单模型神话 |
这个案例能说明 Opus 4.6 的上限很高,也能说明落地门槛不低。若团队没有 CI、代码规范、审计流程,换成任何强模型都很难稳定复现类似结果。
六、国内团队怎么选:单模型思维要换成“组合策略”
在国内环境里,选型不仅看能力,还要看可达性、成本结算、权限管理和故障切换。对大多数团队,建议保留“官方 + 镜像 + 备用域名”三层入口,把稳定性风险从技术层提前移到架构层。
你可以把模型策略设计成下面这套分工:
- 长文档归纳、复杂审计、总控编排交给
Claude Opus 4.6。 - 高频编码、快速重构、短链路修复交给
GPT-5.3。 - 统一在可切换平台内做 A/B 对照,按任务路由而不是按品牌路由。
当你需要国内低门槛访问,可优先准备这些入口关键词:
如果你已经确定把 Claude Opus 4.6 作为主力模型,建议同时准备一个 Grok 备用入口 grok-tool.com,用于网络异常或高峰期切流。
七、从评测到上线:两周迁移清单(可直接照做)
很多团队看完 Claude Opus 4.6 的评测后,会马上进入“全量切换”冲动期。实际更稳妥的路径是做一轮灰度迁移:先选三类任务,分别是长文档分析、跨仓代码审阅、跨角色协同写作。每类任务只保留一个可量化目标,比如“需求漏项率下降 30%”“回归缺陷下降 20%”“周会前材料准备时长减少 40%”。没有量化目标,模型评估很快会退化成主观好恶,团队内部难以达成共识。
执行节奏建议按“基线周 + 试运行周”拆开。基线周只记录旧流程数据,不改提示词,不改角色分工;试运行周再把 Claude Opus 4.6 接进同样流程。这样你拿到的是可比较数据,而不是“换了模型也换了流程”的混合结果。若你的团队已经在使用 GPT-5.3,可以保留它做执行层,把 Claude Opus 4.6 放到计划层和审计层,观察跨文档一致性和返工率是否下降。
迁移过程中最容易被忽略的是上下文治理。建议每个任务都固定三份文件:task-brief.md、decision-log.md、handover.md。task-brief.md 约束目标边界,decision-log.md 记录关键决策与证据,handover.md 负责给下一个智能体或下一个人接棒。只要这三份文件维持更新,Claude Opus 4.6 在长任务中的优势会更稳定地转化为产出质量,而不是只体现在演示视频里。
成本控制不要只看 token 单价。更高频、也更隐蔽的成本是“沟通摩擦”和“重跑次数”。建议把成本拆成三项同时看:模型调用费、工程师等待时长、返工工时。很多团队在这个拆分后会发现,虽然 Claude Opus 4.6 的单次调用更贵,但如果它显著降低回滚次数,总体周成本反而下降。这个结论只有在你把日志、PR 记录和缺陷单串起来看时才会出现。
另一个容易忽略的动作是设置“失败快照”。建议给每次关键失败保留最小复现实例、触发提示词和当时上下文摘要,统一放入同一目录。这样做的价值是,下次遇到同类问题时可以直接回放,而不是重新猜测成因。只要失败经验能结构化沉淀,模型迭代才会真正带来复利。
八、常见问题:评估与上线时最容易卡住的点
1) Claude Opus 4.6 和 GPT-5.3 到底谁更强?
按单一结论回答这个问题价值不大。Claude Opus 4.6 更像长周期任务主引擎,GPT-5.3 更像高频迭代加速器。把它们放进不同工位,收益远高于“只押一个”。
2) Claude Opus 4.6 成本会不会太高?
模型单价只是成本的一部分。更大的成本来自返工和协作摩擦。若 Claude Opus 4.6 能减少跨文档错漏和回滚次数,综合成本反而可能更低。
3) Claude Opus 4.6 适合个人开发者吗?
适合,但要控制任务边界。个人开发者可以先让 Claude Opus 4.6 负责需求拆解与审计,再把执行交给更快的模型,避免在单一会话里堆太多目标。
4) 有没有更稳的国内入口建议?
可以用 AIMirror GPT 中文站 做主入口,再配合 grok-tool.com 做备用链路。对于要交付给业务团队的系统,这种多入口设计比“全员手动翻墙”更可维护。
结语
Claude Opus 4.6 的真正意义,不只是多拿几分基准,而是把“长上下文 + 并行智能体 + 安全治理”做成了一套更接近工程现实的组合。GPT-5.3 在代码速度与基准竞争上依旧强势,两者并不冲突。对国内团队,最佳策略是:把 Claude Opus 4.6 放在高复杂度、长周期、强审计任务,把 GPT-5.3 放在高频执行任务,用统一平台做路由和容灾。